1,521 posts tagged “datasette”
Datasette is an open source tool for exploring and publishing data.
2026
An embarrassingly tiny release. The pyproject.toml had pinned to datasette==1.0a27, inadvertently making this plugin incompatible with all other Datasette versions. It's now datasette>=1.0a27 instead.
I'll write more about this one soon, but it's a big release. Three highlights from the release notes:
- New "Create table" interface in the database actions menu, backed by the
/<database>/-/createJSON API. It can define columns, primary keys, custom column types,NOT NULLconstraints, literal defaults, expression defaults and single-column foreign keys. (#2787)- New "Alter table" table action and
/<database>/<table>/-/alterJSON API for changing existing tables: add, rename, reorder and drop columns; change column types, defaults,NOT NULLconstraints, primary keys and foreign keys; and rename the table. The alter table dialog also includes a "Drop table" button. (#2788)- New Template context documentation listing the variables available to custom templates for Datasette's core pages. Variables documented there are treated as a stable API for custom templates until Datasette 2.0. The documentation is generated from dataclass definitions next to the view code, with tests that compare the documented fields against the actual contexts rendered by the database, table, query and row pages. (#1510, #2127, #1477, #2803)
Here's a rough video demo I made of the new create/alter table feature as part of reviewing the PR:
Datasette Apps: Host custom HTML applications inside Datasette
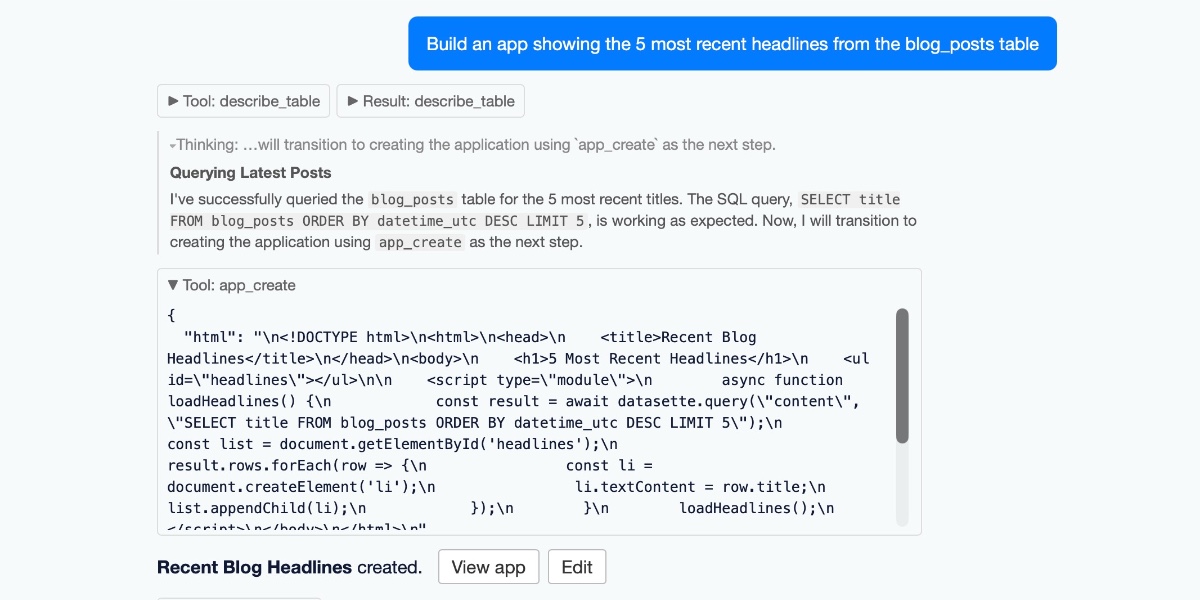
Today we launched a new plugin for Datasette, datasette-apps, with this launch announcement post on the Datasette project blog. That post has the what, but I’m going to expand on that a little bit here to provide the why.
[... 2,301 words]This release expands
datasette-aclfrom table-only permissions toward a general resource-sharing system.
Alex Garcia did most of the work for this release - we're fleshing out the plugin that will allow multi-user Datasette instances finely grained control over who can access which resources within Datasette.
Quoting the release notes:
The big feature in this alpha is tools to insert, edit and delete rows within the Datasette interface. These features are available on table pages, and edit and delete are also available as action items on the row page.
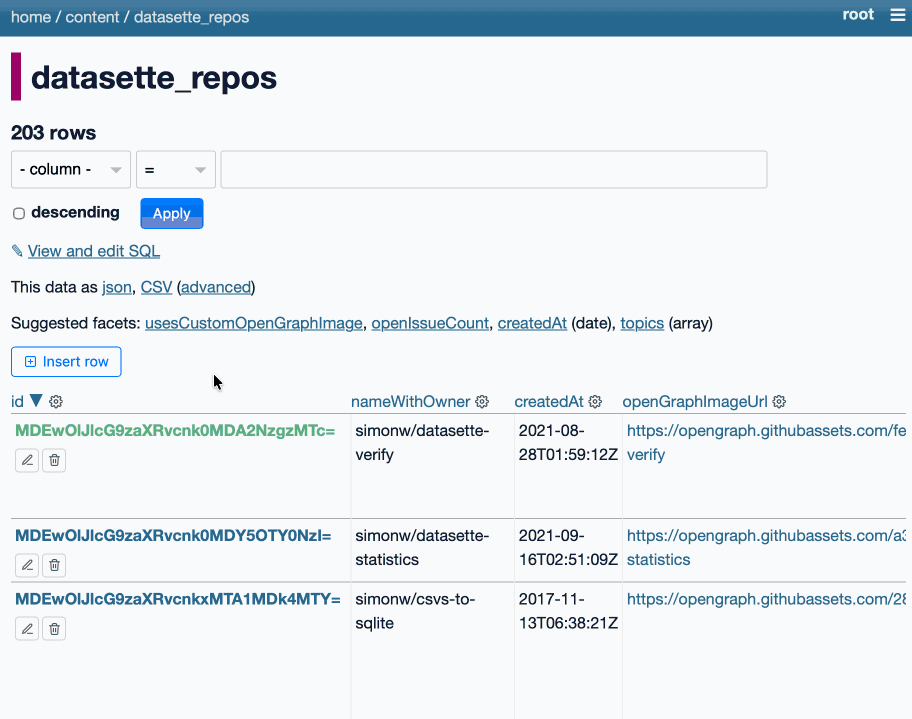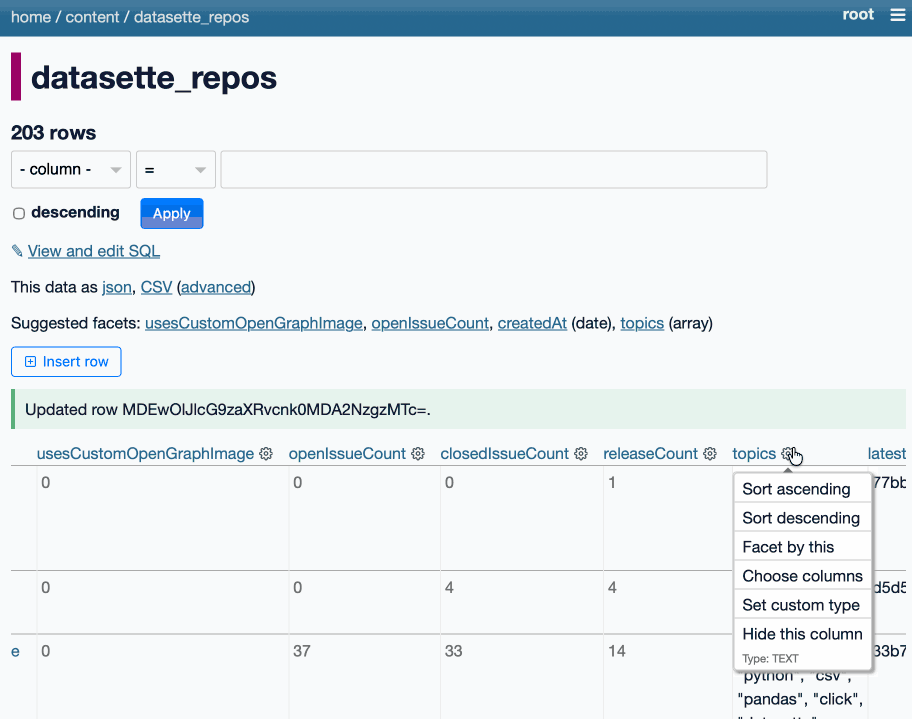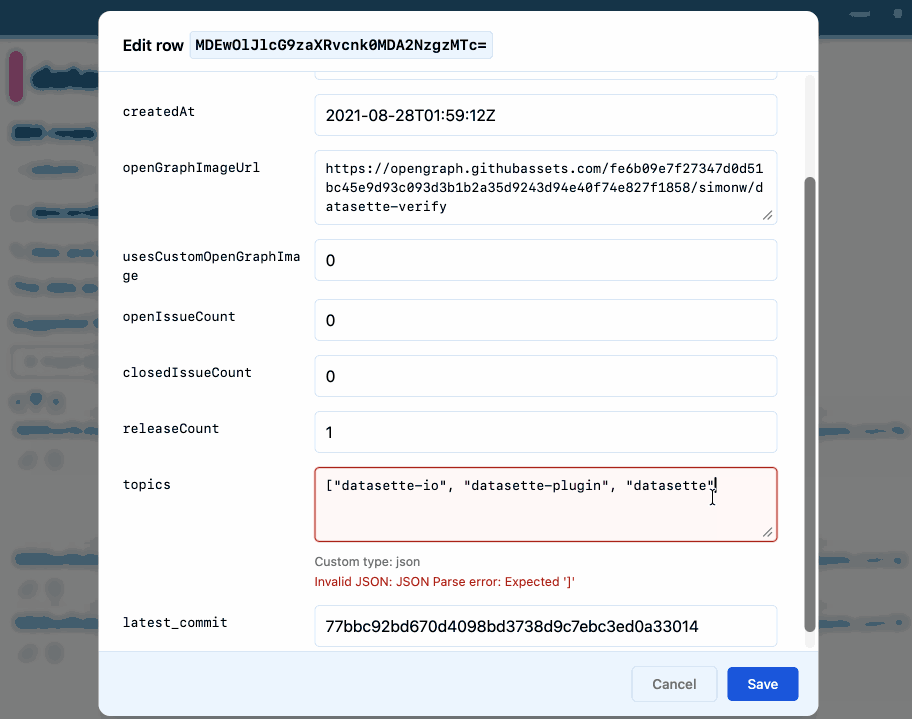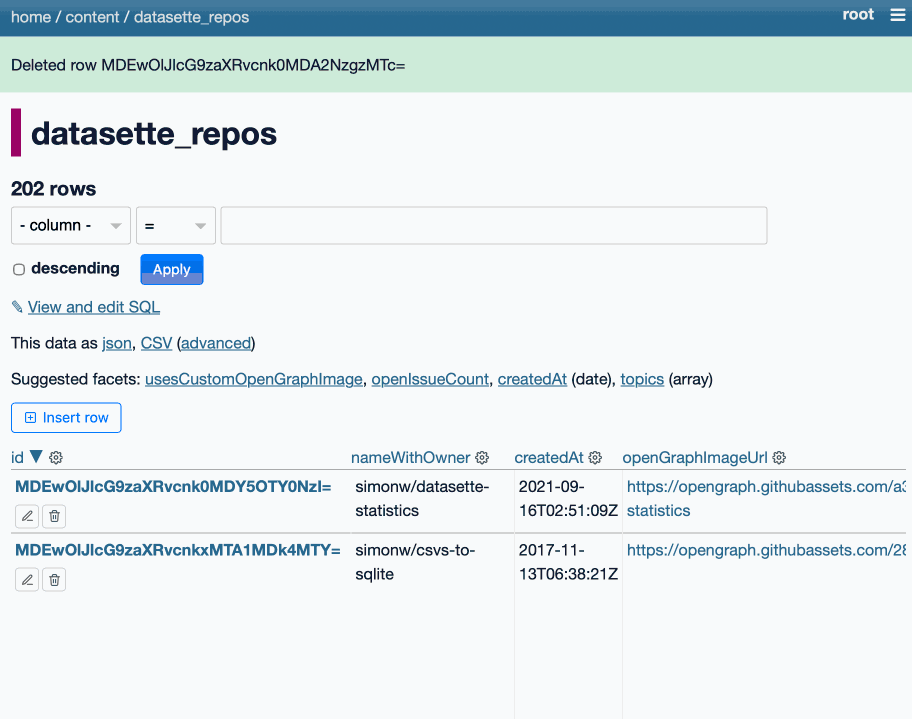
The inspiration for this feature - which is long overdue - was Datasette Agent. I added SQL write support to that the other day which highlighted how absurd it was that you could insert and edit ties via the chat interface but not in the regular Datasette UI!
A very experimental alpha plugin which lets you do this:
datasette tailscale mydata.db \
--ts-authkey tskey-auth-xxxx --ts-hostname datasette-preview
This starts a localhost Datasette server with a Tailscale sidecar that connects it to your Tailnet, such that http://datasette-preview/ serves Datasette.
It's using the Python bindings for the experimental tailscale-rs library. I filed an issue asking if there's a cleaner way of setting up the proxy mechanism.
- Fixed a bug where users without the
create-apppermission could still create apps. #27- Fixed a bug where it was impossible to grant permission to edit an app to users who were not the app's owner. The rules for edit/delete are now the same as view: if the app is private only the owner can modify it, otherwise permission is controlled by Datasette's regular permission system. #29
- Custom network/CSP origins for apps are now guarded by a new
apps-set-csppermission, with an optionalallowed_csp_originsplugin allow-list for non-privileged users. The Datasette Agent app creation tool enforces the same rules. #24- Stored query picker now supports keyboard navigation and shows the three most recent accessible stored queries when focused.
#fragmentlinks inside apps are no longer intercepted by the external-link confirmation modal. #23- Fixed link confirmation modal and logging panels in
?full=1full-screen mode. #26
- New tool,
execute_write_sql, which requests user approval and then writes to a database - taking user permissions into account. #27
I added a mechanism for asking user approval in datasette agent 0.2a0. The new execute_write_sql tool can now prompt the user for all kinds of useful operations. Here's an example where I add some pelican sightings to my pelican_sightings table:
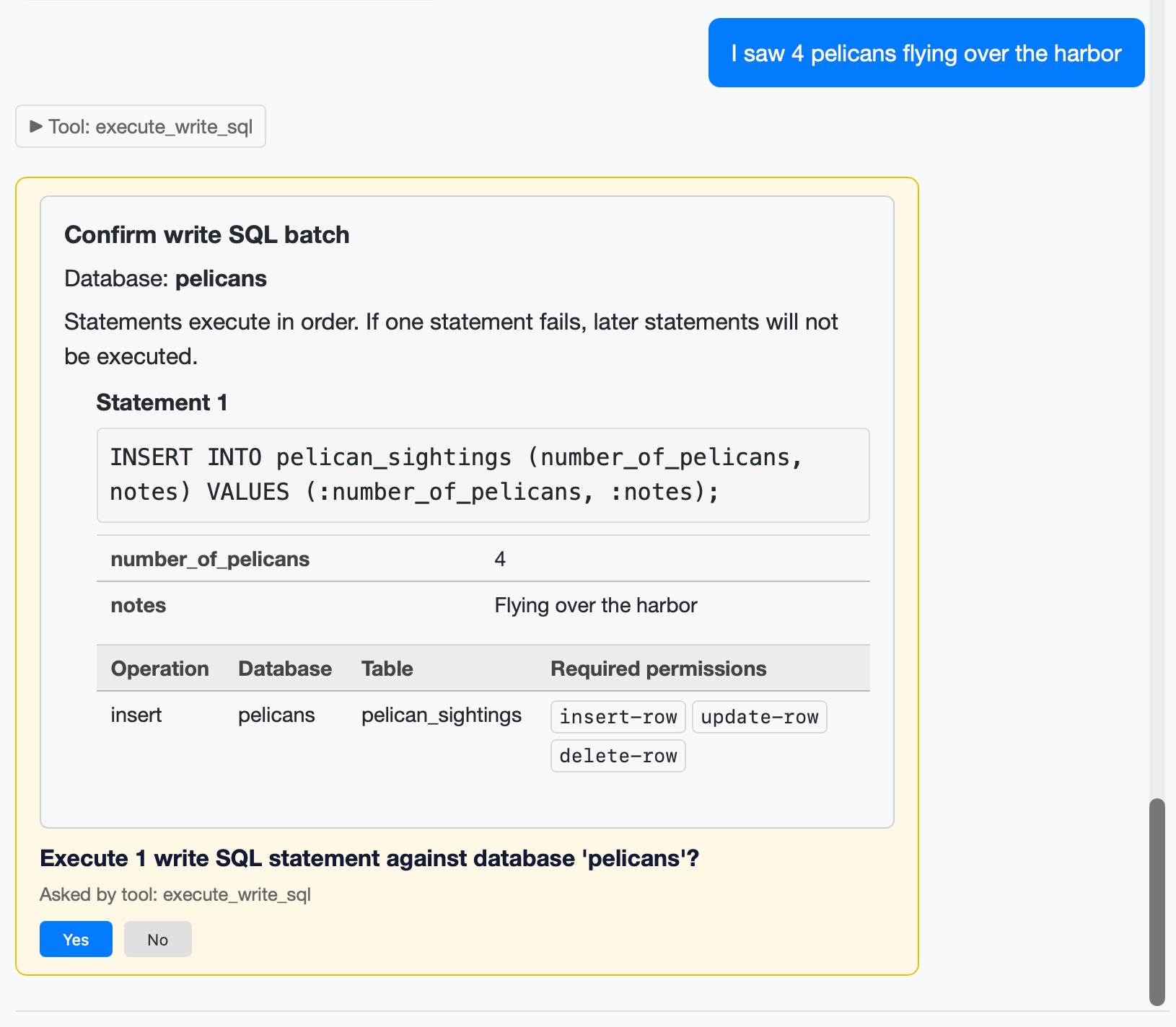
The new version also enhances the datasette agent chat terminal mode to support approvals, and adds several new options including --unsafe mode for auto-approving them:
datasette agent chatcan execute tools that require user approval. #30- Three new options for
datasette agent chat---rootto run as root,--yesto approve all ask user questions, and--unsafefor both.- Tools can now provide plain text alternatives to HTML, for display in the
datasette agent chatCLI. #31
The datasette agent chat content.db -m gpt-5.5 --unsafe command can now be used to chat directly with a specific database and directly modify it through prompts like "create a notes table", "add a note about X" etc.
It would be neat if arbitrary SQL queries in Datasette could be rendered with additional information based on which columns from which tables were included in the results.
To build that, we would need to be able to look at a SQL query like select users.name, orders.total from users join orders on orders.user_id = users.id and programmatically identify the table.column for each result - navigating not just joins but also more complex syntax like CTEs.
I decided to set Claude Code (Opus 4.8, since Fable is currently banned by the US government) on the problem. It found several promising solutions - one using apsw, another that uses ctypes to access the SQLite sqlite3_column_table_name() C function (which is not otherwise exposed to Python), and one using clever interrogation of the output of EXPLAIN.
This alpha is a significant step on the road to a stable 1.0, finally extending the ?_extra= pattern I introduced in Datasette 1.0a3 to cover queries and rows in addition to tables. That pattern is also now documented!
I wrote a whole lot more about the new release on the Datasette project blog: Datasette 1.0a33 with JSON extras in the API.
Because API explorer tools are almost free to build now I had Claude Fable 5 in Claude Code (for the plan) and GPT-5.5 xhigh in Codex Desktop (for the implementation) build me this custom extras API explorer to help demonstrate the feature:
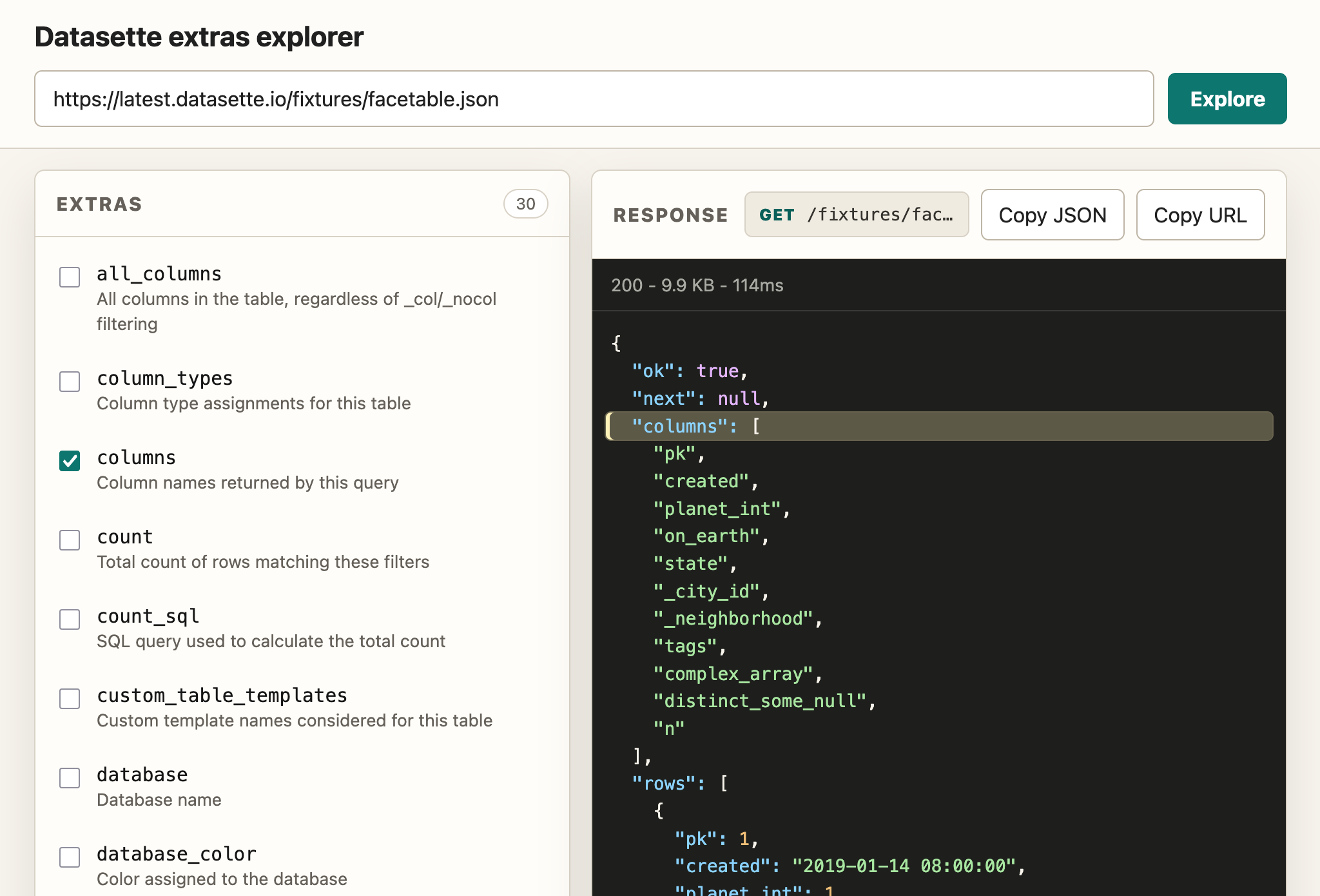
Highlights from the release notes:
- Tools can now ask the user questions mid-execution. Tools that declare a
contextparameter receive aToolContextobject, andawait context.ask_user(...)can ask a yes/no, multiple-choice (options=[...]) or free-text (free_text=True) question. While a question is unanswered the agent turn suspends: the question renders as a form in the chat UI and persists to the internal database, so suspended conversations survive a server restart. Once answered, the tool re-executes from the top with stored answers replayed, so callask_user()before performing side effects. #20- New built-in
save_querytool: the agent can save SQL it has written as a Datasette stored query. Saving always requires human approval - the agent shows the full SQL plus the proposed name, database and visibility, and nothing is stored until you click Yes. #20
The ask_user() feature was enabled by the new LLM alpha I built yesterday with the help of Claude Fable 5.
- Switch to using
MessageChannel()to communicate between parent and child frames. #15- Now registers tools to Datasette Agent can create and modify apps. #16
- SQL queries and
console.log()executed by an app are now shown in a collapsible logging panel. #20- Full screen mode for apps. #21
- Performance optimizations for the create/edit pages. #22
I'm planning several plugins for Datasette Agent which can make edits to existing pieces of text - things like collaborative Markdown editing, updating large SQL queries, and editing SVG files.
Agentic editing of text is a little tricky to get right. My favorite published design for this is for the Claude text editor, which implements the following tools:
view- view sections of a file, with line numbers added to every line.str_replace- find an exactold_strand replace it withnew_str- fail if the original string is not uniqueinsert- insert the specified text after the specified line number
Rather than recreate these patterns for every plugin that needs them I decided to create this base plugin, datasette-agent-edit, which implements the core tools in a way that allows them to be adapted for other plugins.
Running Python code in a sandbox with MicroPython and WASM
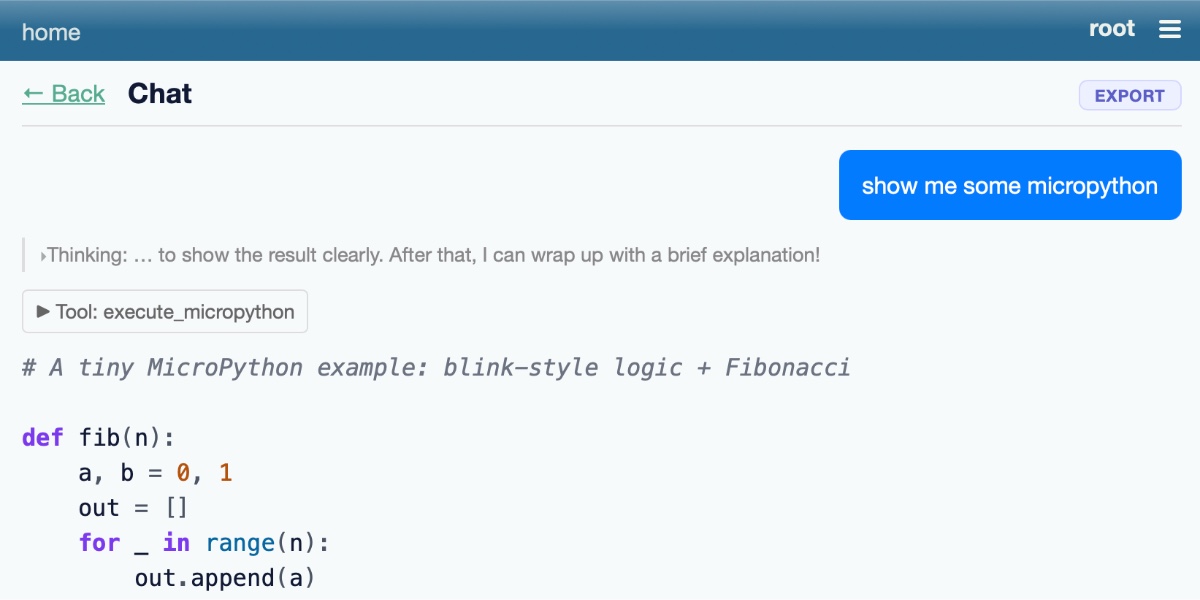
I’ve been experimenting with different approaches to running code in a sandbox for several years now, but my latest attempt feels like it might finally have all of the characteristics I’ve been looking for. I’ve released it as an alpha package called micropython-wasm, and I’m using it for a code execution sandbox plugin for Datasette Agent called datasette-agent-micropython.
[... 2,024 words]First alpha release.
I want Datasette Agent to be able to generate and execute Python code safely. This alpha is looking promising so far. GPT-5.5 has so far failed to break out of the sandbox!
A minor bugfix release. Fixes a bug with INSERT ... RETURNING queries via the new /db/-/execute-write endpoint and a bunch of base_url issues which showed up when I was experimenting with Service Workers yesterday.
Datasette Lite is my version of Datasette that runs entirely in the browser using Pyodide in WebAssembly.
When I first built it four years ago I used Web Workers and code that intercepts navigation operations and fetches the generated HTML by running the Python app.
This worked, but had the disadvantage that any JavaScript in <script> tags would not be executed - breaking some Datasette functionality and a whole lot of Datasette plugins.
This morning I set Claude Opus 4.8 the task (in Claude Code for web) of figuring out how to run Python ASGI apps in Pyodide using Service Workers instead, and it seems to work! Here's a basic ASGI FastCGI demo and here's a demo that runs Datasette 1.0a31.
I'm still getting my head around exactly how it works, but once I've done that I plan to upgrade Datasette Lite itself.
Another significant alpha release, with two new headline features.
Datasette now offers users with the necessary permissions the ability to both execute write queries against their database and to save stored queries (renamed from "canned queries") both privately and for use by other members of their Datasette instance.
There's more detail in SQL write queries and stored queries in Datasette 1.0a31 on the Datasette blog, which now has three posts introducing new features since the blog launched two weeks ago.
Here's an animated demo from the blog post showing how the new execute query interface lets people get started with templated insert/update/delete queries from tables they have permission to edit:
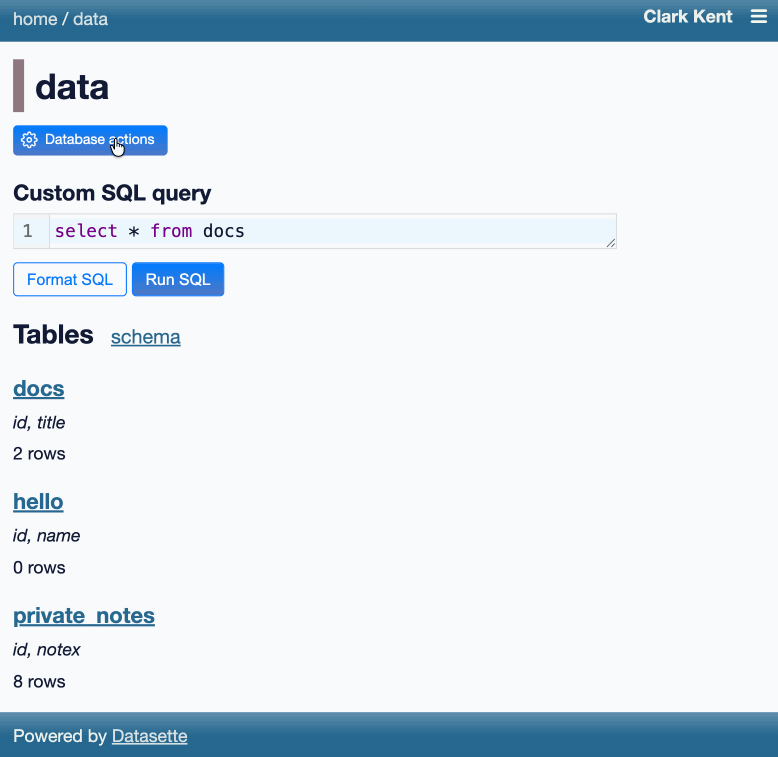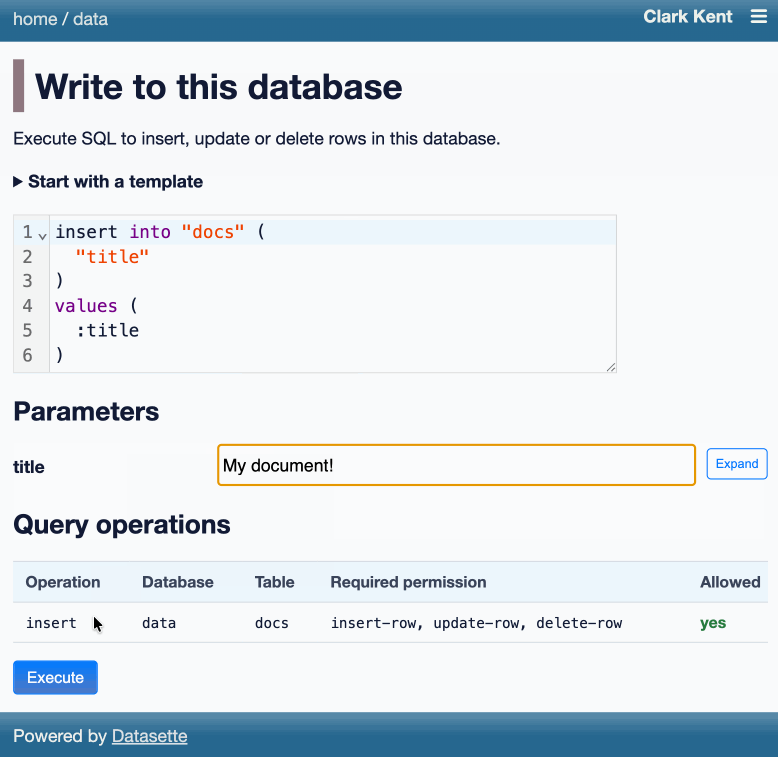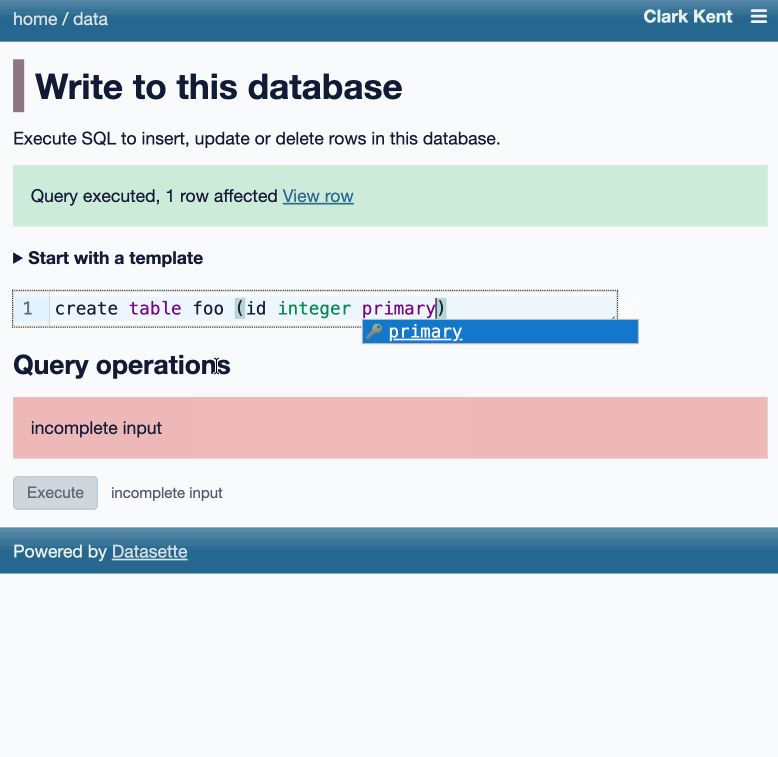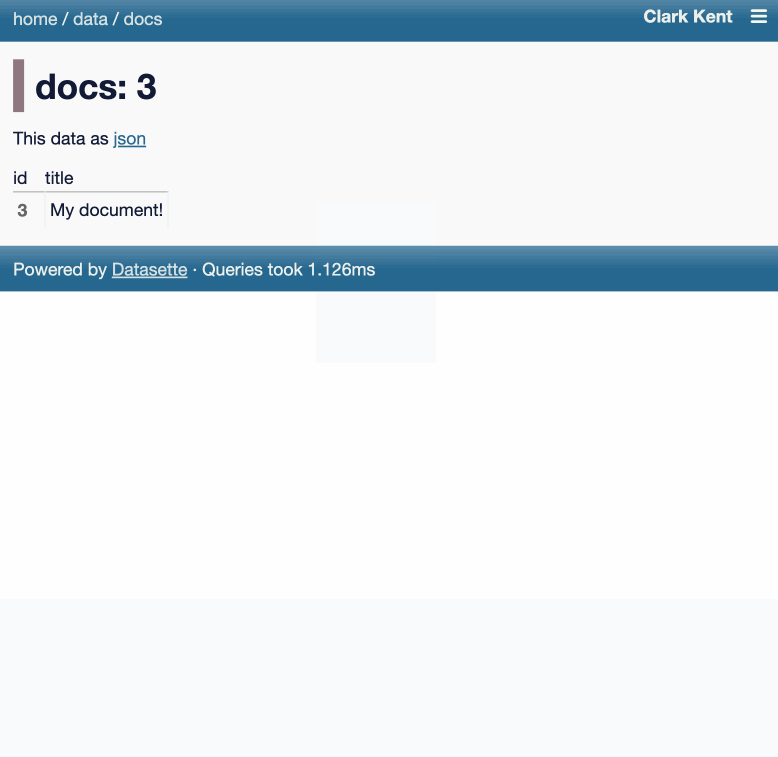
I think Anthropic and OpenAI have found product-market fit
Anthropic are strongly rumored to be about to have their first profitable quarter. Stories are circulating of companies surprised at how expensive their LLM bills are becoming from usage by their staff. I think this is because OpenAI and Anthropic have both found product-market fit.
[... 1,931 words]The big new feature in this alpha is a new customizable "Jump to..." menu, described in detail in The extensible "Jump to" menu in Datasette 1.0a30 on the Datasette blog. You can try it out by hitting / on latest.datasette.io - it looks like this:

The new jump_items_sql() plugin hook allows plugins to add their own items to the set that's searched by the plugin.
Taking advantage of the new makeJumpSections() JavaScript plugin hook added in Datasette 1.0a30, datasette-agent now presents this "Start a new agent chat" interface as part of the Jump to menu, any time you hit /:
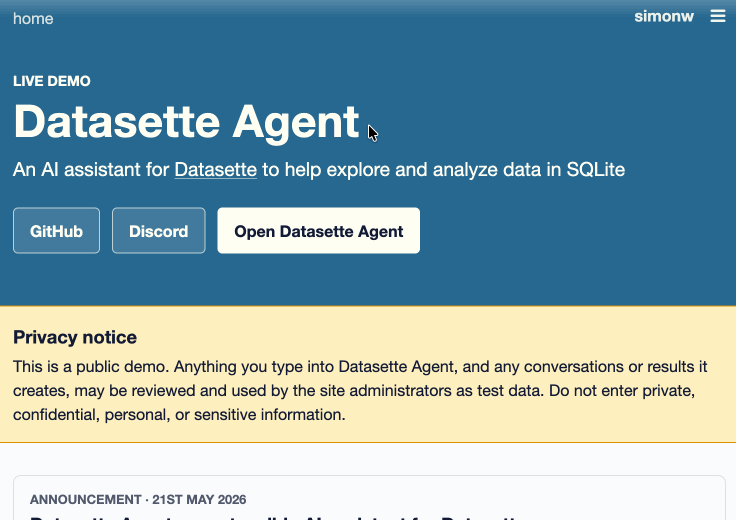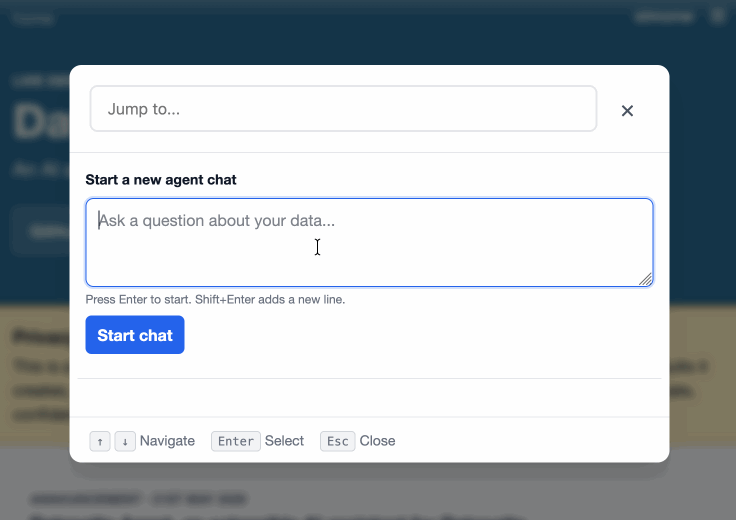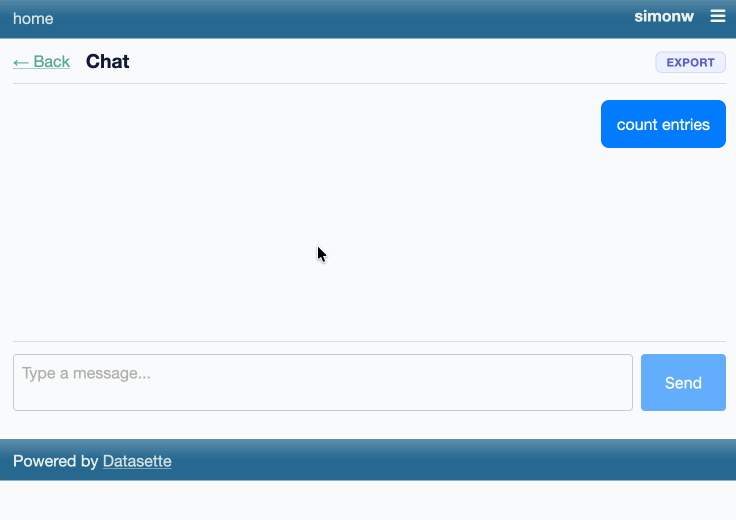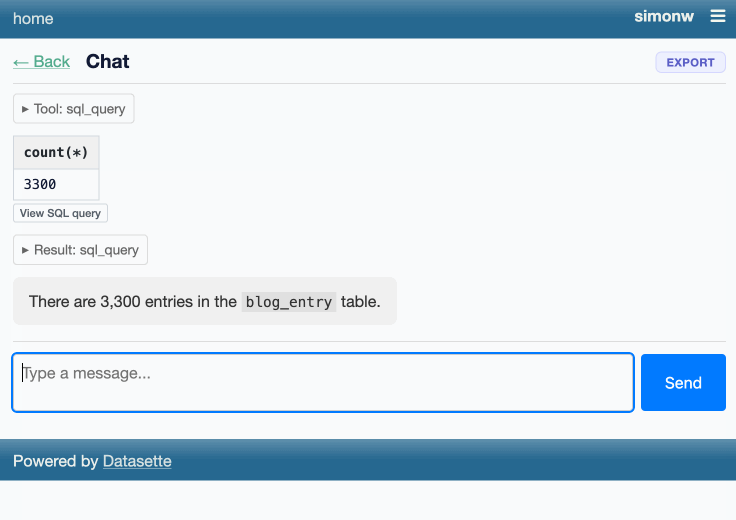
You can try this out by signing into agent.datasette.io using your GitHub account.
One of the smaller features in Datasette 1.0a30 is this:
New documented datasette.fixtures.populate_fixture_database(conn) helper for creating the fixture database tables used by Datasette's own tests, intended for plugin test suites.
This new plugin takes advantage of that API. You can try it out using uvx without even installing Datasette like this:
uvx --prerelease=allow \ --with datasette-fixtures datasette \ --get /fixtures/roadside_attractions.json
Which outputs:
{
"ok": true,
"next": null,
"rows": [
{"pk": 1, "name": "The Mystery Spot", "address": "465 Mystery Spot Road, Santa Cruz, CA 95065", "url": "https://www.mysteryspot.com/", "latitude": 37.0167, "longitude": -122.0024},
{"pk": 2, "name": "Winchester Mystery House", "address": "525 South Winchester Boulevard, San Jose, CA 95128", "url": "https://winchestermysteryhouse.com/", "latitude": 37.3184, "longitude": -121.9511},
{"pk": 3, "name": "Burlingame Museum of PEZ Memorabilia", "address": "214 California Drive, Burlingame, CA 94010", "url": null, "latitude": 37.5793, "longitude": -122.3442},
{"pk": 4, "name": "Bigfoot Discovery Museum", "address": "5497 Highway 9, Felton, CA 95018", "url": "https://www.bigfootdiscoveryproject.com/", "latitude": 37.0414, "longitude": -122.0725}
],
"truncated": false
}
- Improved design of the
/-/llm-limitspage, now using the base template. #2- Now shown in application menu for users with the
datasette-llm-limits-viewpermission.
Datasette Agent
We just announced the first release of Datasette Agent, a new extensible AI assistant for Datasette. I’ve been working on my LLM Python library for just over three years now, and Datasette Agent represents the moment that LLM and Datasette finally come together. I’m really excited about it!
[... 659 words]A Datasette Agent plugin for running commands in a Fly Sprites sandbox.
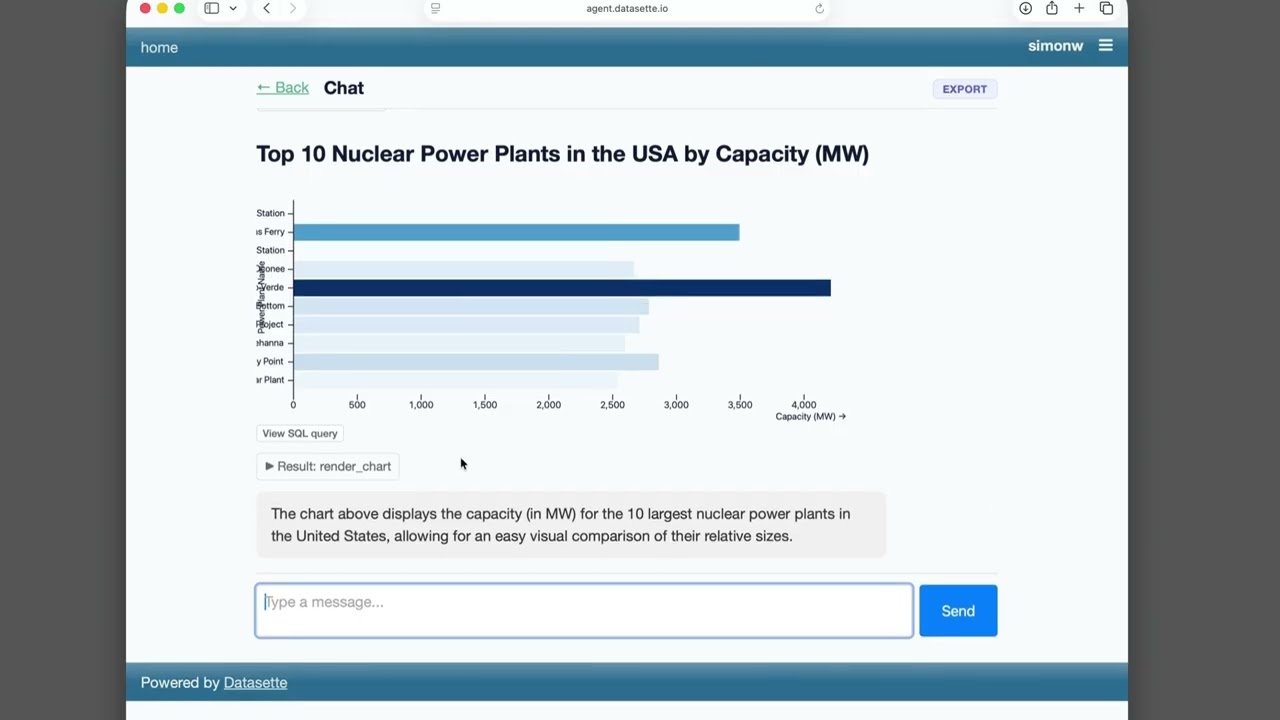
- "View SQL query" buttons below rendered charts.
- "View SQL query" buttons for both visible tables and collapsed SQL result tool calls.
- Don't display empty reasoning chunks
- Improved handling of truncated responses - table still displays to the user even if the SQL results were truncated when showing the agent.
See Datasette Agent, an extensible AI assistant for Datasette.
- More color! Bar and waffle charts without a color column are shaded by magnitude with a sequential color scheme; color columns holding text values use the
observable10categorical scheme. #2- Now checks
execute-sqlpermission before running the query to find the column names.- Charts now display interactive tooltips.
- Fixed a bug where
waffleYcharts were not described to the agent.